





MENGUASAI STATISTIK PARAMETRIK
(Singgih Santoso, 2015)
STATISTIK APLIKATIF
Statistik Induktif/Inferensi, statistik yang digunakan untuk pengambilan keputusan. fungsi menganalisis data sedangkan statistik deskriptif hanya melihat gambaran data yang dihasilkan dan dianalisis dengan gambaran tersebut.
Bentuk Data:
Data Kualitatif, data yang disajikan bukan dalam bentuk angka seperti nama, status, jenis pekerjaan, gender dsb. data kualitatif terbagi atas:
Data Nominal, data dalam bentuk kategorisasi misal nama barang, tipe barang, jenis pekerjaan, walaupun misal diberi angka, angka tersebut sebagai penanda saja untuk pengelompokan. Tidak dapat dilakukan operasi matematika (penjumlahan, pengurangan, pembagian, dsb)
Data Ordinal, data yang dikelompokkan atau dikategorisasikan tetapi masih ada hubungan urutan. misal urutan rangking, pengelompokan kepuasan
Data Kuantitatif, data yang disajikan dalam bentuk angka, data kuantitatif terdiri atas
Data Interval, data yang diperoleh dengan cara pengukuran, tetapi tidak bermula dari 0 mutlak, contoh data ini adalah suhu: -20, 0, 20 C
Data Rasio, data yang diperoleh dengan pengukuran dan mengenal 0 mutlak atau dari titik start yang sama semua, misal : berat badan, jumlah barang
Uji Validitas dan Reliabilitas
Dalam penelitian khususnya metode survei yang membuat dan mengukur dengan skala Likert, maka harus dipastikan instrumen kuesioner kita adalah layak dan dapat diuji, Sikap konsumen yang kita ukur dengan angka agar menjadi data kuantitatif yang bagus maka harus diuji terlebih dahulu
(Analysis-Scale-Reliability Analysis) aktifkan ITEM, SCALE, SCALE IF ITEM DELETED
hasilnya akan ada tabel item-total statistik dan tabel cronbach's alpha, bandingkan antara cronbach alpha dan cronbach alpha if item deleted. misal Cronbach Alpha = 0,868 apabila pada cronbach alpha if item deleted > dari 0,868 maka sebaiknya item tersebut dihapus karena akan meningkatkan cronbach alpha nya.
Uji Validitas Konstruk
uji validitas adalah untuk mengukur konstruk yang menyusun variabel apakah valid atau tidak, jika kita menyakan senang itu dengan 3 pertanyaan seperti merasa bersemangat, merasa bahagia, merasa nyaman maka perlu diuji validitas konstruknya untuk mengukur variabel senang tersebut
(Analysis-Dimension Reduction-Faktor) kelompokkan pertanyaan-pertanyaan yang menyusun variabel, lalu klik ROTATION, pada bagian METHOD pilih VARIMAX, buka OPTION, Klik SUPPRESS SMALL COEFFICIENT, dan tampil ABSOLUTE VALUE BELOW disisi dengan 0,50
Beda Parametrik dan Non Parametrik
Apabila jumlah sampel sedikit (kurang dari 30) dan/atau berupa data nominal atau ordinal menggunakan non-parametrik, apabila jumlah sampel (>30 dan data rasio dan interval) menggunakan parametrik. gambaran nya adalah:
Parametrik:
Data > 30
Distribusi normal
Data interval atau rasio
Analisis Univariat (hanya pengukuran satu variabel) sedangkan Analisis Multivariat (banyak variabel)
STATISTIK PARAMETRIK
Statistik Deskriptif, untuk melihat gambaran data agar lebih informatif dalam menampilkan data, adapun menu-menu yang ditampilkan dalam SPSS antara lain:
Olap Cubes, menampilkan data secara praktis dengan berbagai menu. (analyze-Report-OLAP cubes)
Case Summaries, menyajikan ringkasan suatu variabel (Analyze-Report-Case Summaries)
Descriptive, memberikan gambaran tentang suatu data seperti rata-rata, deviasi, variasi dsb (Analyze-Descriptive Statistics-Descriptive)
Frequencies, menggambarkan data secara lengkap dengan beberapa pilihan (Analyze-Descriptive Statistic-Frequencies)
Explore, penyajian data deskriptif yang selain memberikan gambaran data juga dapat digunakan untuk melihat Outlier (data yang tidak terdistribusi normal) caranya (Analyze-Descriptive Statistic-Explore)
Crosstab, penyajian data dalam bentuk tabulasi (Analyze-Descriptive Statistic-Crosstab)
Uji Beda (Uji t)
Statistik Induktif/Inferensi
Uji satu sisi dan Uji dua sisi
Uji satu sisi adalah pernyataan yang H0 dan H1 mengandung pertidaksamaan yang mengarah pada kriteria tertentu. Contoh : menguji apakah penurunan berat badan menggunakan Obat A efektif?
sedangkan Uji dua sisi adalah pernyataan yang H0 dan H1 mengandung pertidaksamaan seperti: apakah penjualan mobil di daerah semarang sama dengan penjualan mobil di daerah surabaya?
Secara umum penggunaan uji t untuk melihat sampel dua kelompok apakah ada perbedaan atau tidak dengan persyaratan sebagai berikut:
Jumlah sampel relatif kecil (<30), jika sampel besar menggunakan uji z
Sampel yang diambil berdistribusi normal atau mendekati normal (jika tidak normal biasanya banyak Outlier nya)
Besaran t hitung ditentukan dengan varians kedua populasi yang diuji sama dan varians kedua populasi diuji berbeda
Uji t satu sampel (One sample t Test)
uji ini untuk mengetahui apakah sebuah nilai tertentu yang diberikan sebagai pembanding berbeda secara nyata atau tidak dengan rata-rata sampel.
contoh mengukur penjualan roti salah seorang sales apakah berbeda dengan yang lain?
(Analyze-Compare means-One sample T-test)
Uji t Dua Sampel Bebas (independent sample t-Test)
uji ini untuk membandingkan rata-rata dua grup yang tidak berhubungan satu dengan yang lain, dengan tujuan apakah kedua group mempunyai rata-rata yang sama ataukah tidak?
contoh : menghitung perbedaan prestasi penjualan roti susu dari para sales dengan tingkat pendidikan mereka?
(Analyze-Compare means-Independent sample t test)
Uji t Dua Sampel Berpasangan (Paired Sample t Test)
untuk menguji apakah dua sampel yang berpasangan beda atau tidak,
Contoh: Penjualan roti menggunakan kemasan lama pada beberapa kota, lalu kemudian diganti menggunakan kemasan baru
(Analyze-Compare Means-Paired-Sample Test)
Uji Beda ANOVA (Uji F)
menguji beda lebih dari dua sampel dan jumlah sampel >30, dan apabila variabelnya lebih dari satu maka menggunakan MANOVA untuk uji bedanya.
Contoh: Perbedaan penjualan roti kacang, roti susu, roti coklat dan roti keju (4 jenis sampel)
(Analyze-Compare Means-One Way ANOVA)
Contoh 2: Mengetahui perbedaan antara sales penjualan Roti A, B, C dan D?
(Analyze-General Linear Model-Univariate)
Uji Beda MANOVA (Uji F)
jika variabel lebih dari 1 maka menggunakan MANOVA, fungsi sama yaitu untuk menguji perbedaan antara data dua kelompok/group.
contoh: menguji beda data apakah rata-rata penjualan dan persepsi konsumen berbeda pada tiap kota?
(Analyze-General Linear Model-Multivariate)
Repeated Measure
untuk mengetahui perbedaan pada suatu variabel atau atribut yang diukur secara berulang-ulang. mirip uji t berpasangan, tapi repeated mouse ini untuk data yang berulang-ulang setelah dikenakan tindakan.
Contoh: mengetahui apakah ada perbedaan penjualan produk dengan adanya penayangan iklan beberapa kali?
(Analyze-General Linear Model- Repeated Measure)
KORELASI
termasuk analisis bivariat yaitu mengukur hubungan antara dua variabel, dimana variabel dianalisis bersama-sama. misala seberapa besar iklan mempengaruhi sales(Variabel Dependen/Y)? dan seberapa besar motivasi dan Lingkungan kerja mempengaruhi kepuasan kerja (Variabel dependen)\
“Beda Korelasi dan Regresi adalah Korelasi bertujuan untuk mempelajari apakah ada hubungan antara dua variabel atau lebih sedangkan regresi memprediksi seberapa besar pengaruh tersebut.”
Korelasi Pearson
Menghitung korelasi dua variabel dengan data keduanya interval/rasio
Contoh: mencari hubungan antara gaji, usia dan pengalaman?
(analyze-Correlate-Bivariate)
Sig > 0,05 maka H0 = diterima artinya (negasi atau tidak ada hubungan)
Sig <0,05 Maka H0 ditolak artinya ada hubungan
Tanda ** pada Korelasi pearson menunjukkan kekuatan hubungannya kalau positif hubungannya semakin besar variabel A maka mempengaruhi secara positif dengan kekuatan yang besar
Angka Korelasi Pearson menunjukkan kekuatan mempengaruhinya

Pearson Correlation nya adalah kekuatan mempengaruhinya, semakin mendekati 1 semakin kuat, dan tanda ** menunjukkan kuat pengaruhnya
Tanda Sig (2-Tailed) 0,000 menunjukkan ada hubungan karena dibawah 0,05
N = jumlah sampel
Korelasi Parsial
sama seperti korelasi pearson mengetahui hubungan antara dua variabel tetapi bisa menambahkan variabel tambahan lain yang berfungsi sebagai pengontrol
Contoh : Hubungan antara Gaji dan Usia dengan pengalaman sebagai variabel kontrol
(Analyze- Correlate-Partial)
Korelasi Spearman dan Kendall
adalah korelasi untuk mengetahui hubungan variabel dengan data ordinal
Contoh : Menghitung hubungan antara prestasi kerja, IQ dan Loyalitas (data ordinal)
(Analyze-Correlate-Bivariate)
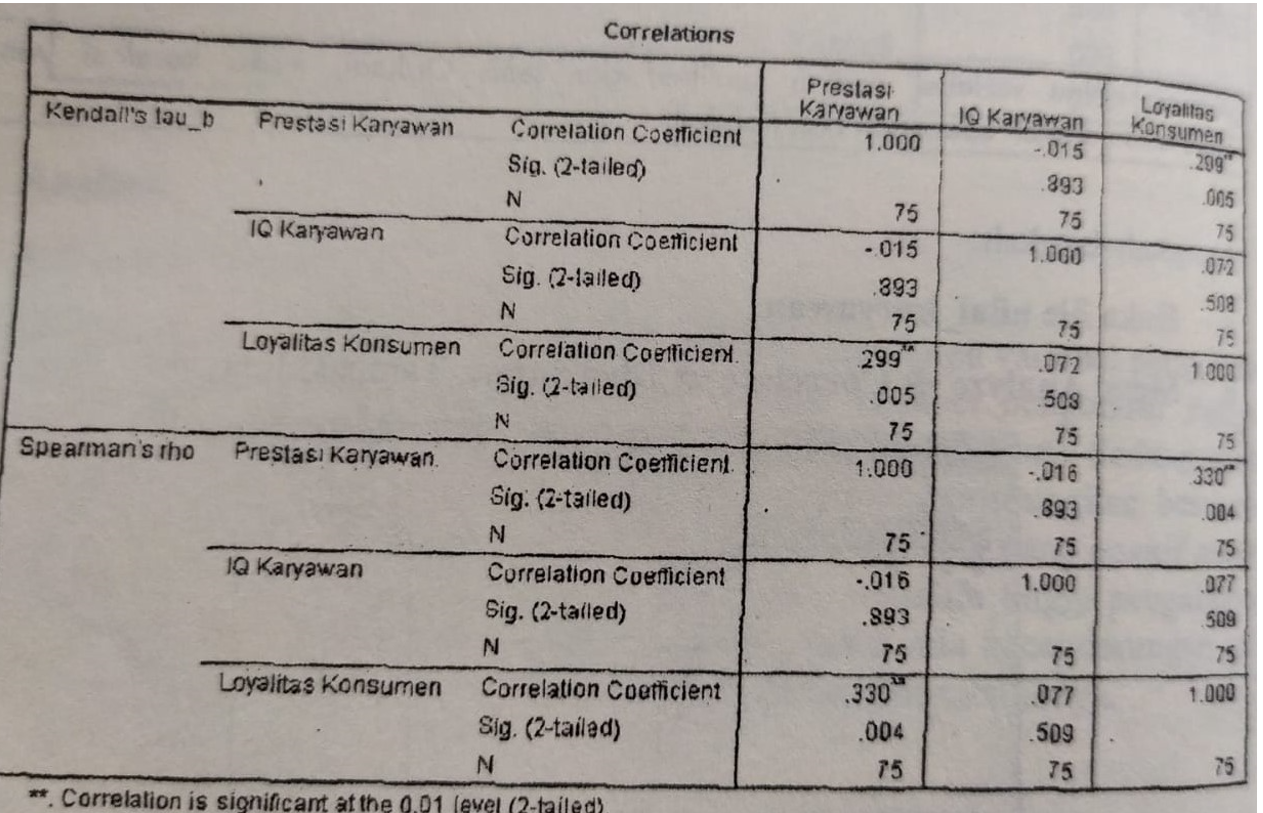
Cara membacanya adalah:
Membaca dari tabel row nya (ada korelasi Kendall's) Row pertama adalah Prestasi karyawan sedangkan untuk kolom pertama juga prestasi karyawan, itu pasti sama hubungannya identik, lalu kolom ke 2 yaitu IQ karyawan, jadi hubungan prestasi karyawan dengan IQ adalah (Sig 2-tailed = 0,893) angka ini diatas >0,05 maka H0 (negasi diterima) artinya tidak ada hubungan antara prestasi kerja dan IQ tetapi untuk kekuatan hubungan (kalau misal ada adalah sebesar -0,015, kecil sekali dan berlawanan artinya semakin besar prestasi karyawan maka IQ nya semakin kecil), kemudian masih di row sama prestasi karyawan dengan loyalitas konsumen, nilai signifikansinya adalah 0,005, angka ini lebih kecil dari 0,05 maka H0 ditolak (negasi ditolak) artinya ada hubungan prestasi kerja dengan loyalitas konsumen dan kekuatannya adalah sebesar 0,299, ada hubungan yang positif tapi tidak terlalu besar prestasi karyawan mempengaruhi loyalitas konsumen walau tidak terlalu besar kekuatan pengaruhnya.
Tabel Row kedua adalah IQ karyawan dengan Prestasi karyawan nilainya sama jadi pengaruh ini dua arah atau saling mempengaruhi, pada kolom kedua iq karyawan dengan iq karyawan hasilnya pasti sama, lalu Iq karyawan dengan loyalitas konsumen signifikansinya = 0,0508 masih di atas 0,05 artinya ada tidak ada hubungan tapi mendekati ada hubungan hampir 0, sedangkan kekuatannya apabila ada hubungan adalah sebesar 0,072 (sangat kecil)
Tabel Row ketiga adalah Loyalitas konsumen, semua sudah memiliki hubungan semua, jadi bisa langsung disimpulkan
Grafik Scatter Plot
Melihat hubungan atau korelasi pada sebuah grafik, grafik yang memiliki hubungan akan membuat pola tertentu
(Graphics-Legacy Dialogs-Scatter/Dot)
REGRESI
memprediksi kekuatan dan bahkan membuat formula hubungan antara dua variabel. Output dari analisis regresi adalah sebuah rumusan persamaan
Contoh : Y = a + b. X
Gaji = konstanta + (Koefisien regresi) x Pengalaman kerja
Fungsi utamanya adalah untuk memprediksi variabel dependen nya, misal setelah kita tahu perumusan konstanta dan koefisien, maka kita dapat memprediksi gaji/variabel dependennya
Regresi Sederhana
mencari formulasi analisis hubungan satu variabel (bebas) dengan variabel terikatnya
Regresi Berganda
mencari analisis formulasi lebih dari dua variabel, perlu diingat agar formulasi benar dan baik maka data harus normal dan terlebih dahulu diuji dengan uji signifikansi / normalitas.
(Analyze-Regression-Linear)

Hasil dari Regresi / Output SPSS nya adalah sebagai berikut:
pada tabel kedua “Model Summary”, cek tabel tersebut, kolom pertama adalah R = 0,869 menunjukkan hubungan korelasi sales (dependent) dengan iklan di koran, radio, outlet dan salesman yang saling menguatkan dan mempengaruhi variabel dependen (lebih besar dari 0,5 artinya kuat)
R square dan Adjusted R square adalah koefisien determinasi maksudnya adalah sebesar 75,5% (R square dipakai kalau variabelnya satu) atau 71,6% (R adjusted square jika variabelnya lebih dari satu karena kondisi variabel saling mempengaruhi) contoh di atas karena ada iklan koran, iklan outlet dan iklan radio menggunakan Adjusted R Square sebesar 71,6% artinya penjualan dapat dijelaskan sebesar 71,6% karena iklan tersebut pengaruhnya sedangkan sisanya sebesar 28,4% adalah karena faktor lain. lalu pada kolom ujun ada Std.Error of the Estimate = 41,58 jt kemungkinan salah sebesar 41,58 jt.bln, semakin kecil Std errornya maka semakin bagus formula regresinya
Pada Tabel ketiga “ANOVA” kolom ujung Signifikansi = 0,000 lebih kecil dari 0,05 maka H0 ditolak(negasi ditolak) artinya ada hubungan antara penjualan dan iklan
Pada Tabel keempat “ COEFFICIENTS” kita dapat melihat rumus pada konstanta, dan beta nya
Y = a + bX
Sales = 100,123 + {10,913x(iklan koran) + 4,966x(Iklan radio) - 13,275x(jumlah outlet) - 13,988x(jumlah salesman)}
artinya: jika kita mengabaikan iklan koran dan radio serta outlet dan salesman maka potensi penjualan adalah sebesar 100,123, dan setiap variabel-variabel lain akan berkontribusi sesuai konstanta tersebut dan dari sini juga kita dapat melihat ternyata jumlah outlet dan salesman berpengaruh negatif terhadap penjualan.
Kemudian coba kita lihat Signifikansinya untuk menilai pengaruhnya ternyata Signifikansi Iklan radio = 0,147 dan lebih besar dari 0,05, artinya H0 diterima / negasi diterima artinya tidak ada hubungan iklan radio dengan sales. karena tidak ada hubungan sebaiknya dihilangkan untuk membuat persamaan baru.
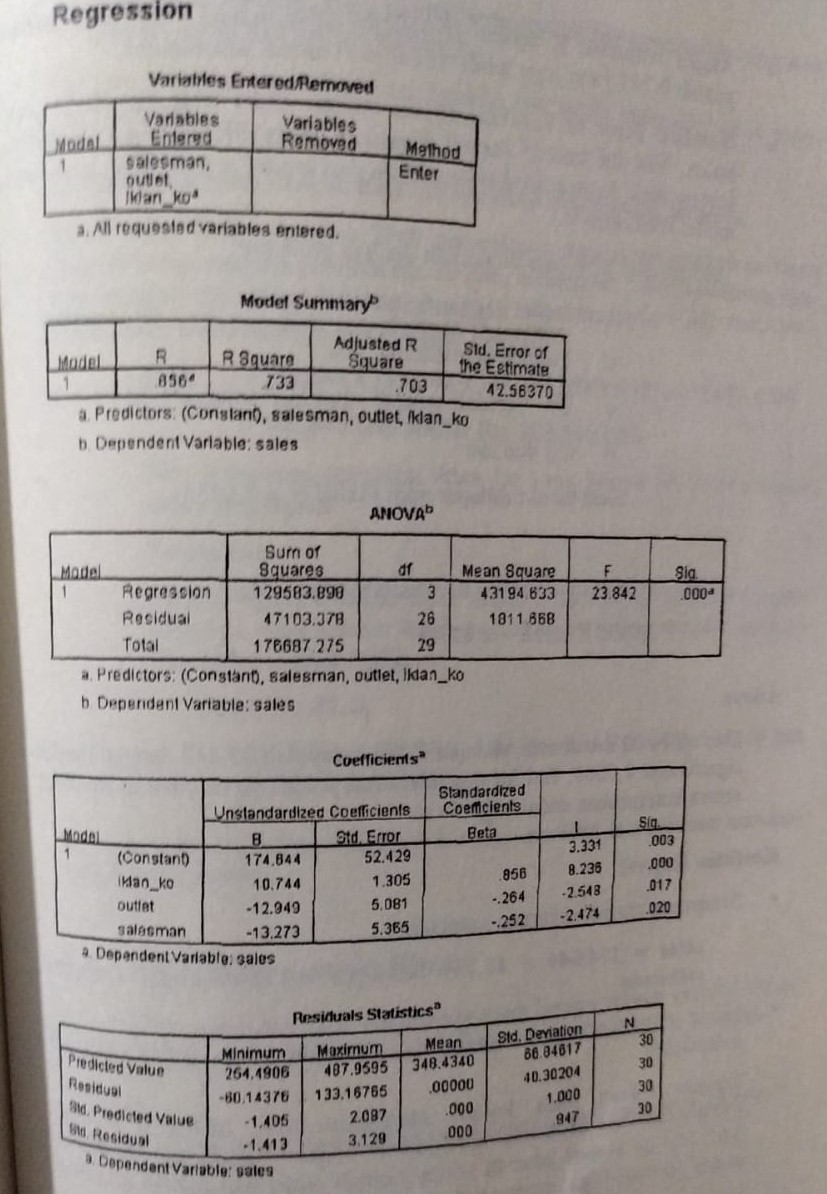
dari persamaan baru tersebut didapatkan:
Pada tabel “Model Summary” R = 0,856 artinya menunjukkan hubungan kekuatan korelasi
R square / Koefisien determinasi 73,3% dan Adjusted R Square = 70,3% menunjukkan kemampuan variabel-variabel menjelaskan sebesar 70.3% nahwa hubungan sales karena variabel iklan koran, omset dan salesman, adjusted R Square jika variabel juga saling mempengaruhi. kemudian Std of Error the estimate nya 42,56, yaitu standar errornya semakin rendah semakin baik.
Pada tabel ke 3 ANOVA , nilai Significant nya 0,000 lebih kecil dari 0,05 artinya H0 di Tolak (negasi tidak diterima) artinya ada hubungan yang kuat
Pada tabel ke-4 Coefficients, menunjukkan rumusan
Y = a + bX
Sales = 174, 64 Jt + {(10,74xIklan Koran) - (12,949 x Outlet) - (13,273xSales)}
sehingga rumusan untuk memprediksi sales/penjualan sudah dapat diperkirakan, misal Biaya iklan = 30 Jt, jumlah salesman ditambah 10 orang dan jumlah outlet 12 maka tinggal masukkan dalam persamaan
Sales = 174,64 + (10,74x30 Jt) - (12,94x12) - (13,273x10)
Sales = 208,846 jt atau Rp 208.846.000
Estimasi standar Error adalah 87,48 (berasal dari tabel Std Error = 42,54 x 2)
Jadi estimasi Sales adalah:
Rp 208,846 Jt plus minus 87,48 Jt
Regresi Berganda Binari
Memprediksi besar variabel tergantung (dependent) yang berupa variabel biner dengan menggunakan variabel bebas yang diketahui besarnya
Variabel Binary adalah variabel yang hanya dua pilihan seperti:
1 = membeli
0 = Tidak membeli
atau gagal dan sukses, mau dan tidak mau
(Analyze-Regression-Binary Logistic)
selalu pastikan signifikasinya hanya yang nilai signifikasinya di bawah 0,05 saja yang diambil karena memiliki pengaruh atau berkorelasi kalau yang nilai signifikasinya >0,05 maka tidak memiliki korelasi dan tidak perlu diuji.
Regresi Berganda dengan Variael Dummy
Data regresi karena tidak mengenai nama adau data nominal dan ordinal maka harus di ganti angka
Contoh apakah ada pengaruh antara gaji yang diberikan dengan gender salesman pria/wanita?
(Analyze-Regression-Linear)
Regresi Berganda Model Polinomial (Kurva)
Memprediksi variabel tergantung dengan daya yang dimiliki data variabel independennya dengan membentuk sebuah model polinomial
Contoh: mengamati hubungan produksi roti sebelum di beri berbagai rasa (variabel bebas) dengan biaya produksi tiap unit sebagai variabel dependen, maka menggunakan Regresi berganda model polinomial
(Analyze-Regression-Curve Estimation)
ASUMSI REGRESI
Sebuah model regresi dapat digunakan apabila memenuhi syarat sejumlah asumsi atau “asumsi klasik” terdapat 5 asumsi pemodelan regresi yaitu:
Normalitas, nilai dari Y (Dependent) seharusnya didistribusikan secara normal terhadap nilai X (Independent)
Linearitas, adanya hubungan bersifat linear antara variabel dependent dan sekelompok variabel independen
Homoskedasitas, variasi disekitar garis regresi seharusnya konstan untuk setiap nilai X
Multikolinieritas, antara variabel X (independent) tidak boleh berkorelasi secara kuat dan significant, jadi sesama variabel independen saling mempengaruhi satu sama lain secara kuat maka model regresi tidak dapat dilaksanakan
Autokrelasi, terjadinya gangguan data yang bersifat time series (situasional atau musiman), model regresi seharusnya berasal dari autokorelasi, sehingga kesalahan prediksi (selisih data asli dengan data hasil regresi) bersifat bebas untuk setiap nilai X
Uji Multikolinearitas
menentukan apakah variabel-variabel independen saling mempengaruhi satu sama lain, sehingga menyebabkan model regresi tidak dapat diterima
(Analyze-Regresi-Linear) aktifkan pilihan Covariance matrix dan Collinearity diagnostics
Pada tabel Coefficient, lihat Collinearity statistiknya. apabila nilai tolerance mendekati 1 dan nilai VIF nya di sekitar 1 maka model regresi tidak terdapat problem MULTIKOLINEARITAS.
pada tabel Coefficient Correlation, angka koefisien korelasinya di bawah 0,05 (artinya lemah)
Uji Homoskedastisitas
Menguji apakah sebuah model regresi, terjadi ketidaksamaan varians residual dari satu pengamatan ke pengamatan yang lain. Jika varians residual dari satu pengamatan ke pengamatan yang lain tetap, maka hal tersebut disebut Homoskedastisitas dan jika berbeda disebut Heteroskedastisitas, dan model regresi yang baik adalah yang Homoskedastisitas.
(Analyze-Regresi- Linear) Plot-
Maka kalau tampilan acak tidak ada pola tertentu maka tidak terjadi Heteroskedastisitas maka regresi dapat diterima
Uji Normalitas
untuk menguji pada model regresi apakah nilai residual dari regresi mempunyai distribusi normal, jika nilai residual tidak berdistribusi normal maka dapat dikatakan ada masalah terhadap asumsi normalitas.
(Analyze-Regresi-Linear) Plot-Normal probability plot
dari gambar dilihat jika data menyebar disekitar garis diagonal maka memenuhi asumsi normalitas.
Uji Autokorelasi
untuk mengetahui apakah ada pengganggu pada model regresi dari periode t dan periode sebelumnya,
(Analyze-Regression-Linear) aktifkan Durbin-Watson
Kesimpulan:
Apabila angka D-W dibawah -2 berarti autokorelasi positif
Apabila angka D-W diantara -2 sampai +2 berarti tidak ada autokorelasi
Apabila angka D-W diatas +2 berarti autokorelasi negatif
pastikan posisi angka D-W (diantara -2 sampai 2)
Data Statistik dibagi menjadi data cross section dan Data Time Series
Data cross section : pada suatu waktu tertentu
Data Time series : data beberapa tahun
Data Time Series terdiri atas:
Trend : data yang dalam jangka panjang membentuk arah
Gerakan siklis : data yang menunjukan pola yang sama dalam kurun waktu tertentu
Gerakan Musim : daya yang menunjukkan pola pada waktu tertentu saja yang sama
Gerakan tak teratur
Trend dengan Moving Average (MA)
upaya untuk memuluskan dan menghaluskan data dan meminimalisir data musiman atau data tak terukur, sehingga dilihat arah jangka panjang
(Transform-Create Time Series) Prior Moving Average
dan untuk menampilkan grafiknya
(Graph-Legacy dialog-line)


0 comments:
Posting Komentar